



【點新聞報道】2025年以來,AI大語言模型從「能對話」向「會思考」快速演進。香港大學經管學院今日(15日)發表《AI高階推理能力評測報告》,深入評測中美共37款主流大語言模型,在中文語境下的高階推理能力。研究團隊首次構建多模態推理和國際數學奧林匹克競賽(奧賽)推理綜合評測體系,旨在評估AI高階推理能力的發展現狀。
評測結果顯示,在「多模態推理」方面,GPT系列持續領先,以「豆包1.5 Pro」(思考模式)為首的頂尖國產模型,亦已成功躋身全球第一梯隊。在更高難度的「奧賽推理」方面,則由美國模型整體主導,其中GPT-5(思考模式)的優勢更可謂表現突出,大幅拋離對手,而Gemini 2.5 Pro亦緊隨其後。
報告指出,專為高階任務設計的「推理模型」表現遠勝「通用模型」,反映AI發展正從追求功能廣泛的「廣度擴張」,邁向聚焦特定場景的「深度精耕」新階段。
領導研究的蔣鎮輝教授表示:「高階推理能力對AI在教育、科研及商業決策等領域的應用拓展至關重要。此研究旨在揭示高階人工智能技術的發展現狀,令行業能夠精準定位技術瓶頸,加速通用人工智能在高要求領域的落地應用,最終推動AI從『對話助手』轉型成為更加高級的『智能夥伴』。 」
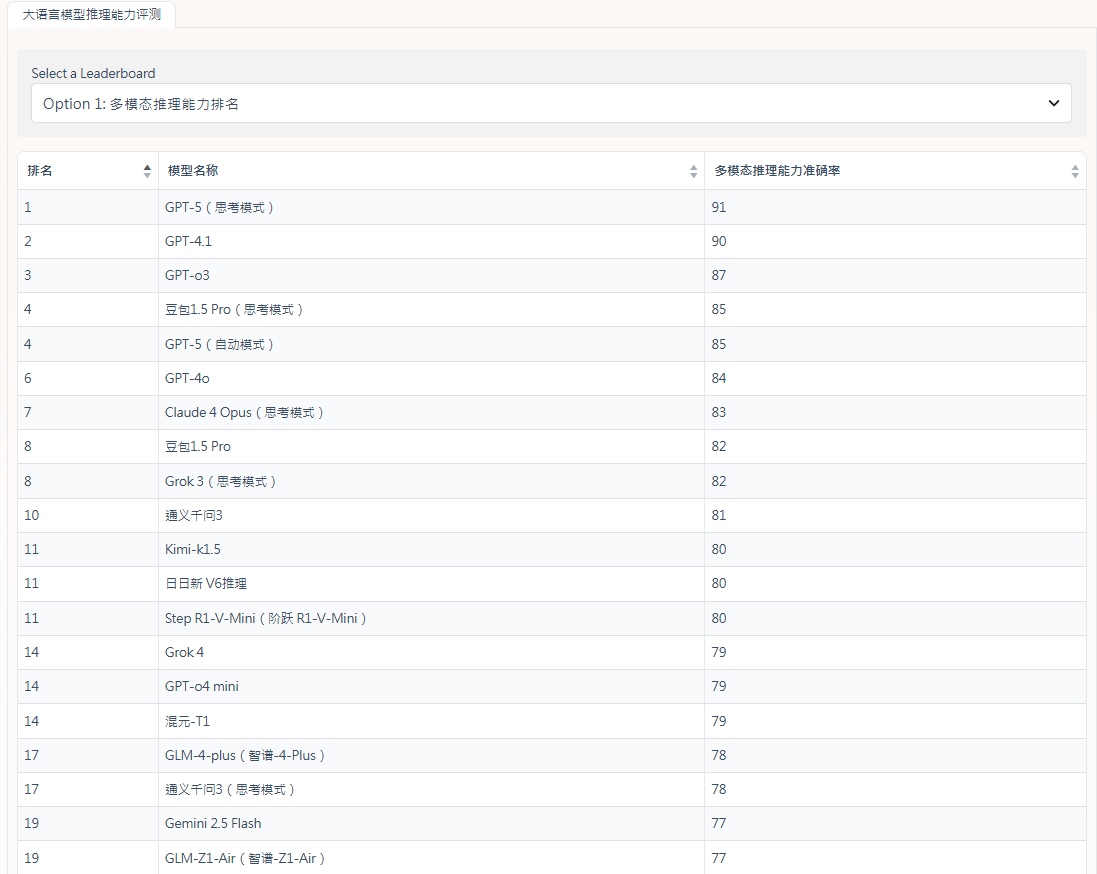
多模態推理能力排名
大語言模型在「多模態推理能力」上的表現出現明顯分層。其中,GPT系列展現出全面的領先優勢。內地研發的「豆包1.5 Pro」(思考模式)成為唯一打入前五名的國產模型,值得留意的是,其「通用模式」與「思考模式」的評分差距極小,證明其多模態推理的底層實力已達到國際頂尖水平。
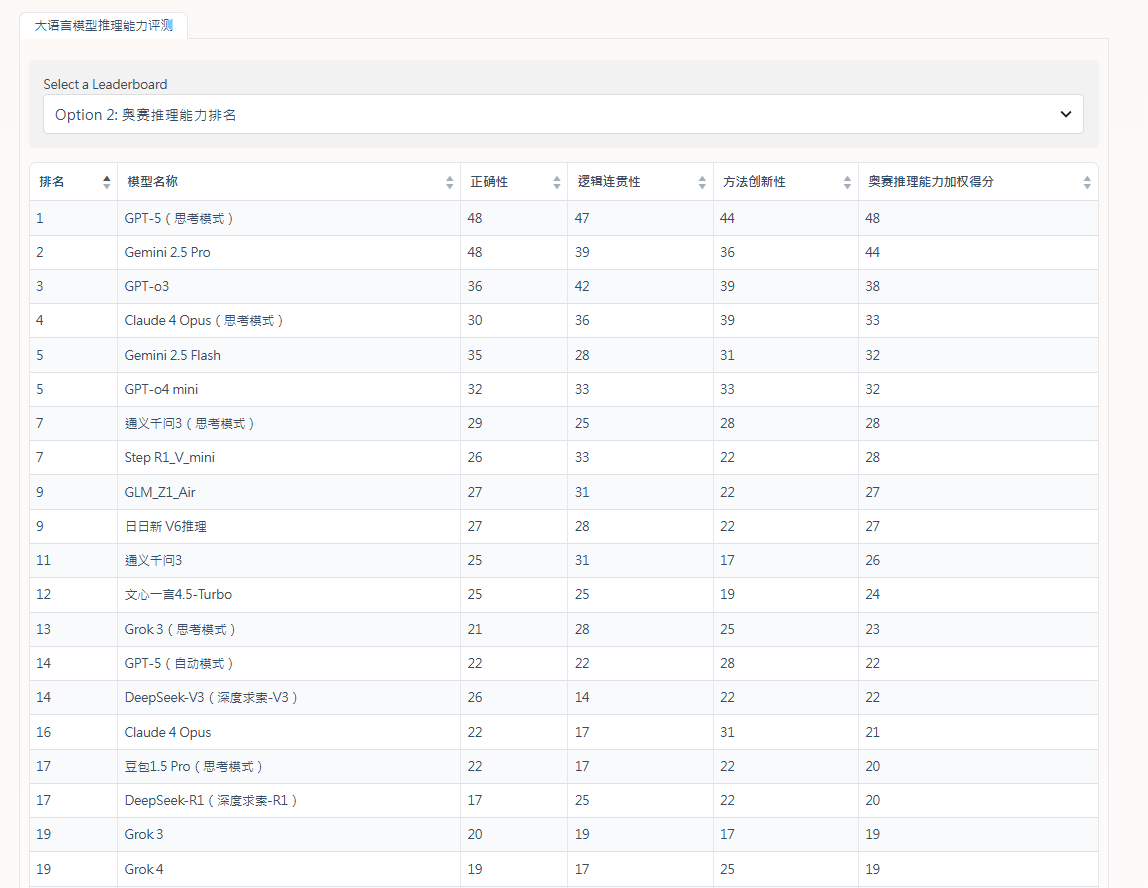
奧賽推理能力排名
在「奧賽推理能力」方面,處於龍頭位置的是GPT-5(思考模式)和Gemini 2.5 Pro,以絕對優勢遙遙領先。至於國產模型的表現,「通義千問3」(思考模式)和Step R1_V_mini表現尚可,反映國產模型在處理頂尖複雜推理任務上,仍有相當大的進步空間。此外,即使是同一間公司旗下的模型,思考模式下的模型在各項奧賽推理維度上的表現,普遍優於其通用模型。
相關閱讀:

